Audio AI Recognition Market: By Type (Music recognition, Speech recognition, Disability assistance, Surveillance systems, Natural sounds recognition); Device (Smartphones, Tablets, Smart Home Devices, Smart Speakers, Connected Cars, Hearables, Smart Wristbands and Others); Deployment (On Cloud, On-Premises/Embedded); Industry (Automotive, Enterprise, Consumer, BFSI, Government, Retail, Healthcare, Military, Legal, Education, Others); region—Industry Dynamics, Market Size, Opportunity and Forecast for 2025–2033
- Last Updated: Jan-2025 | Format:
![pdf]()
![powerpoint]()
![excel]() | Report ID: AA1122331 | Delivery: 2 to 4 Hours
| Report ID: AA1122331 | Delivery: 2 to 4 Hours


 | Report ID: AA1122331 | Delivery: 2 to 4 Hours
| Report ID: AA1122331 | Delivery: 2 to 4 Hours Market Scenario
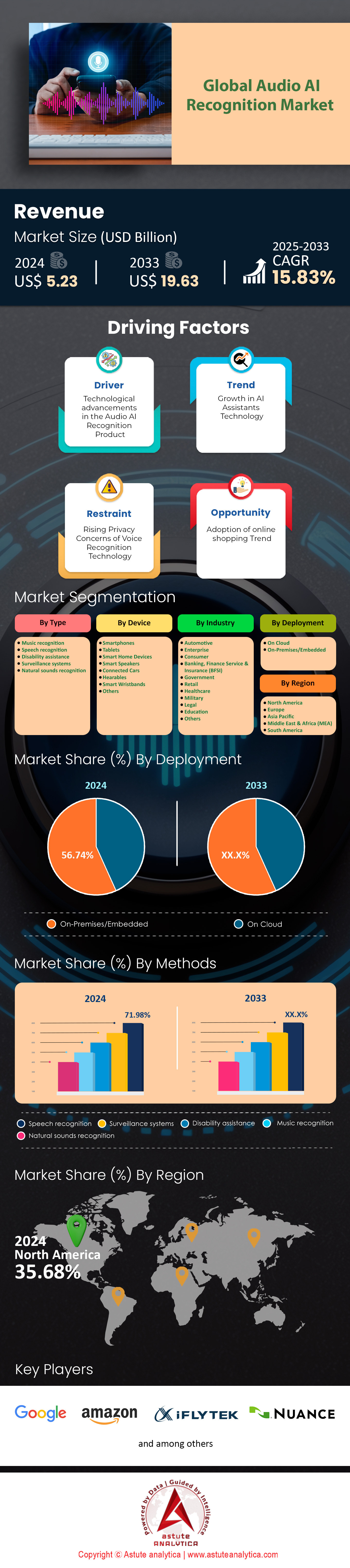
Audio AI recognition market was estimated at US$ 5.23 billion in 2024 and projected to surpass valuation of US$ 19.63 billion by 2033 at a CAGR of 15.83% during forecast period 2025–2033.
The demand for audio AI recognition continues its remarkable climb, driven by heightened consumer expectations for seamless voice interactions and accurate speech analytics. At the core of this surge lie technologies like deep learning neural networks, natural language processing, and voice biometrics, all of which cater to applications involving real-time transcription, virtual assistants, and security authentication. Among the leading end users are call centers, healthcare professionals, and the automotive sector, each requiring robust voice capabilities for tasks such as agent performance monitoring, patient data documentation, and in-car control. In 2024, the audio AI landscape witnessed 230 new AI-enabled microphone arrays introduced to the market, with 67 outright launches of voice-based security solutions. Additionally, 12 products integrated wavelet-based feature extraction methods to counter noisy environments.
Key industries adopting Audio AI recognition market include banking to expedite customer verification, media outlets to automate content curation, and education providers for rapid lecture transcription. Furthermore, healthcare has embraced AI-powered speech solutions to reduce clinician workload, while entertainment companies enhance user experiences with voice-activated controls. Recent software developments encompass real-time language translation modules and dynamic emotion recognition engines, fostering deeper user engagement. In 2024, 104 specialized voice biometrics offerings were documented across major platforms, and 61 global financial institutions incorporated voice authentication within their mobile banking apps. Major devices capitalizing on these advancements include smart speakers, wearable hearing aids, automotive infotainment consoles, and mobile phones.
Prominent products in the Audio AI recognition market feature Google Assistant, Amazon Alexa, Apple’s Voice Control, and IBM Watson Speech to Text, showcasing high accuracy and versatile integrations. Brands such as Microsoft, Baidu, and iFlyTek spearhead innovation with continuous improvements in latency reduction, language coverage, and contextual understanding. In 2024, 38 in-car voice assistants entered worldwide markets, 29 new hospital-grade voice-to-text solutions were deployed, and 15 gaming titles introduced voice moderation capabilities. Furthermore, 110 contact center deployments of AI-driven speech analytics were tracked globally, demonstrating how organizations across sectors leverage audio AI to refine efficiency and deliver elevated user experiences.
To Get more Insights, Request A Free Sample
Market Dynamics
Driver: Expanding consumer adoption of advanced voice-activated interfaces that deliver highly personalized, truly human-like interactions
The primary driver in audio AI recognition market revolves around the mounting user appetite for fluid, voice-activated experiences that go beyond basic command-based functions. Consumers increasingly demand intuitive chatbots and hands-free assistants in cars, homes, and workplaces, prompting companies to refine speech clarity, contextual understanding, and emotional intonation. In 2024, developers released 42 smart home systems with integrated conversational AI that detect user sentiment, while 35 automotive manufacturers equipped dashboards with sophisticated natural language capabilities. The push for nuanced voice responses has also led to 19 newly launched libraries designed to match individual speech patterns. Meanwhile, user engagement and satisfaction soared with 54 solutions that offer real-time language switching between regional dialects.
Driving adoption further is the rising expectation for deeply personalized interactions, such as speaker-recognition features that identify voices within multi-user households or offices. This functionality fosters tailored recommendations for music, news, or scheduling. In 2024, 28 companies deployed advanced voice biometrics to distinguish up to ten unique speakers in a single environment. Moreover, 17 solutions introduced live emotion detection to modulate responses based on user tone in the Audio AI recognition market. Such innovations highlight how businesses leverage voice AI to forge an almost human connection, fortifying brand loyalty and day-to-day convenience. Notably, development teams are investing resources to fine-tune accent comprehension, rolling out 23 new acoustic modeling frameworks supporting distinct pronunciations. As consumer acceptance of these cutting-edge voice interfaces surges, the market gains unstoppable momentum, making this driver a pivotal factor in shaping the direction of audio AI technology.
Trend: Integration of multi-lingual speech synthesis engines within cross-platform digital ecosystems for highly immersive interactions
A leading trend reshaping Audio AI recognition market is the move toward robust multi-lingual speech synthesis, where systems seamlessly switch among diverse tongues and dialects within a single conversation. This capability underpins real-time translation for global conferences, collaborative online platforms, and multi-regional customer support. In 2024, research labs unveiled 21 advanced text-to-speech engines that replicate natural inflections across four languages simultaneously. Pioneering developers produced nine sophisticated voice fonts catering to varied cultural contexts. Furthermore, cross-platform integration surged, with 14 new software development kits enabling interoperable speech solutions across mobile devices, desktops, wearables, and automotive systems. These breakthroughs underscore a market ambition to unify language models and speech synthesis under one versatile framework.
Increasing demand for immersive interactions in entertainment, e-learning, and collaborative workspaces further propels this trend. Audio AI solutions now deliver narration in multiple languages for massive open online courses (MOOCs), bridging linguistic barriers. In 2024, 16 streaming services launched multi-lingual dubbing features powered by deep neural voices that approximate native nuances . Meanwhile, 11 global universities adopted adaptive language tutoring systems assisted by bilingual speech synthesis in the Audio AI recognition market. The synergy between localized linguistic models and advanced voice generation further refines user engagement, ensuring that instructions, conversations, and media experiences resonate convincingly in any preferred language. Developers introduced five specialized modules with real-time script scanning to decide voice style based on context. As cross-platform ecosystems continue flourishing, this trend positions audio AI as a universal tool for bridging global communication gaps and enriching digital experiences.
Challenge: Ensuring robust acoustic data protection amid escalating concerns about misuse of captured voice insights
The foremost challenge in audio AI recognition market involves securing voice data from unauthorized access, manipulation, or unintended exploitation. With sensitive biometric markers embedded in vocal patterns, companies and consumers worry about potential identity theft, unauthorized recordings, or malicious data inference. In 2024, security analysts documented 14 significant cases of voice data hacking attempts targeting call centers. Meanwhile, 22 specialized solutions emerged to encrypt real-time voice streams, mitigating hacking vulnerabilities. This push toward protection also includes employing four advanced hashing algorithms specifically optimized for acoustic data. To preserve user trust, developers must confirm that collection practices comply with strict privacy guidelines, especially when storing voice data on cloud infrastructures.
Public awareness of voice manipulation further compounds this challenge in the Audio AI recognition market. Deepfake-based attacks and fraudulent voice impersonations highlight how easily captured voice samples can be weaponized if not properly secured. In 2024, five high-profile investigations scrutinized the misuse of cloned celebrity voices for commercial gain. Additionally, eight regulatory bodies called for mandatory acoustic encryption standards across major industries. Organizations responded by investing in advanced anomaly detection protocols, resulting in the creation of nine specialized auditing tools that identify unauthorized usage of stored utterances. Ensuring robust data protection has become crucial not only for legal compliance but also for maintaining brand credibility in a market where user trust is paramount.
Segmental Analysis
By Type
Speech recognition leads the audio AI recognition market with over 71.98% market share due to its widespread adoption across industries and consumer applications. Major providers such as Google (Assistant), Amazon (Alexa), Microsoft (Azure Speech to Text), IBM (Watson Speech Services), and Apple (Siri) dominate this segment. For instance, Google Assistant is integrated into over 3 billion devices globally, while Amazon Alexa powers more than 85,000 types of smart home devices. Microsoft’s Azure Speech to Text is widely used in enterprise applications, offering real-time transcription capabilities for large-scale projects. IBM Watson Speech Services is a key player in healthcare and enterprise sectors, with its solutions adopted by thousands of organizations worldwide. Nuance Communications, a leader in medical transcription, has developed Dragon Medical, which incorporates over 300,000 healthcare-specific terms, making it a preferred choice for clinical documentation.
The dominance of speech recognition in the audio AI recognition market is driven by its ability to enhance user convenience and productivity. Apple’s Siri processes billions of requests annually, reflecting strong consumer reliance on voice-enabled interactions. In the automotive sector, voice-activated navigation systems are integrated into over 300 vehicle models, improving safety and user experience. Additionally, speech recognition is widely used in customer service, with call centers handling millions of voice queries daily. The healthcare industry also benefits significantly, with hospitals using speech-to-text solutions for medical transcription tasks. These applications highlight the versatility and efficiency of speech recognition, making it a cornerstone of the audio AI recognition market.
By Devices
Smartphones dominate the audio AI recognition market by capturing over 33.0% market share due to their ubiquity and the increasing reliance on voice assistants for daily tasks. Google Assistant is pre-installed on over 3 billion Android devices worldwide, while Apple’s Siri is available in 40 countries, showcasing their global reach. Samsung’s Bixby, integrated into over 100 million Galaxy smartphones, further highlights the penetration of voice assistants in mobile devices. The average smartphone user interacts with voice assistants 17 times per week, primarily for tasks like messaging, navigation, and quick searches. Additionally, speech-to-text functionality in smartphone apps processes millions of transcription requests daily, reflecting robust usage trends.
The higher penetration of Audio AI recognition market in smartphones is driven by advancements in hardware and AI capabilities. Qualcomm’s Snapdragon processors, featuring neural processing units, enable real-time voice recognition, while Huawei’s Kirin chipsets support offline speech translation in multiple languages. Popular smartphone-based audio AI solutions include Microsoft’s SwiftKey Voice Input, installed by millions of Android users, and Baidu’s voice assistant, serving a large Chinese-speaking audience. The seamless integration of these tools into messaging, productivity, and entertainment apps fosters consumer loyalty. As smartphones continue to evolve with better AI chips and improved microphones, the adoption of audio AI recognition software is expected to grow further.
By Industry
The consumer industry is the largest end user of Audio AI recognition market due to its integration into everyday products and services. The industry is holding over 25.5% market share and is also poised to keep growing at the highest CAGR of 17.6% in the years to come. Smart speakers, such as Amazon Echo and Google Nest, account for over 200 million units in global circulation, highlighting their widespread adoption in households. Voice-enabled TVs from brands like LG and Samsung are found in millions of homes, demonstrating the popularity of hands-free entertainment control. Wearable devices like Apple Watch and Fitbit integrate voice assistants for quick queries, with Apple Watch shipping tens of millions of units annually to meet rising consumer demand. Wireless earbuds featuring voice assistants, such as Apple’s AirPods, have also seen significant adoption, reinforcing the appeal of portable audio control.
Under the consumer umbrella, households, personal entertainment devices, and wearable tech are key adoption channels in the Audio AI recognition market. Streaming services like Netflix and Amazon Prime incorporate voice search engines to help users navigate extensive catalogs, processing millions of content requests daily. In-car infotainment systems, such as Apple CarPlay and Android Auto, serve millions of drivers worldwide, enhancing convenience and safety. E-commerce platforms like Alibaba and Walmart also facilitate speech-driven purchases, reflecting strong retail interest in voice technology. The dominance of the consumer industry is driven by the desire for hands-free convenience and personalized interactions, supported by robust brand ecosystems and expanding use cases
By Deployment
On-premise deployment leads the audio AI recognition market with over 56.7% market share due to heightened data privacy concerns and regulatory demands in sectors like healthcare, finance, and defense. Hospitals, for example, handle thousands of medical transcription tasks daily, relying on on-premise solutions to safeguard sensitive patient data. Similarly, banks process millions of voice-based customer service calls, making in-house processing critical for compliance with data protection regulations. Leading providers such as Nuance, IBM, and Avaya offer localized solutions deployable in company-owned data centers, ensuring voice data remains secure and private.
Beyond data security, organizations often cite deeper integration flexibility and reduced latency as reasons for choosing on-premise deployment. Enterprises with existing telephony systems find it cost-effective to layer on-premise AI solutions, enabling seamless integration with legacy infrastructure. Contact centers handling millions of voice queries daily benefit from stable, in-house infrastructure that ensures consistent performance. Vendors in the Audio AI recognition market like Genesys and Cisco provide enterprise suites tailored for large-scale usage, further supporting the demand for on-premise deployment. This approach is particularly favored by multinational corporations and government agencies that prioritize data sovereignty and operational control.
To Understand More About this Research: Request A Free Sample
Regional Analysis
North America is the largest audio AI recognition market, with the United States leading due to its advanced tech ecosystem and extensive consumer base. The US has a population of approximately 332 million, creating a vast audience for voice-enabled products and services. Amazon, headquartered in Seattle, has distributed over 105 million Alexa-enabled devices, demonstrating strong adoption among American households. Google’s Assistant, developed in the US, is integrated into over 1 billion devices globally, with a significant portion in North America. Apple’s Siri processes billions of requests annually, reflecting its widespread use in the region. Microsoft’s Azure Cognitive Services and IBM Watson Speech Services are widely adopted by enterprises, further solidifying the US’s leadership in the market.
The region’s dominance in the audio AI recognition market is also driven by high smartphone adoption, with approximately 294 million smartphone users in the US alone. Venture capital funding for AI startups remains robust, with billions of dollars invested in speech technology and related innovations. This financial backing encourages the development of advanced features like multi-accent recognition and live multilingual translation. Additionally, telecom carriers in North America are rapidly upgrading to 5G, enabling near-instant audio query processing on smartphones. The region’s tech-savvy population, combined with strong financial resources and a well-developed ecosystem of providers, ensures North America remains a leader in the audio AI recognition market.
Key Audio AI Recognition Market Companies:
- Amazon.com, Inc.
- Uniphore
- Speechmatics
- SoapBox Labs
- Otter.ai
- Verbit
- Mobvoi
- Nuance
- iFLYTEK
- Sensory
- Other prominent players
Recent Developments in Audio AI Recognition Market
- SoundHound's Acquisition of Amelia SoundHound AI, a leader in voice artificial intelligence, acquired Amelia, a prominent enterprise AI company, for $80 million on August 8, 2024. This acquisition is particularly significant as it expands SoundHound's capabilities in the AI space, especially in voice recognition and AI-driven solutions.
- Capacity's Strategic Acquisitions Capacity, an AI software company, made multiple strategic acquisitions in 2024 to bolster its voice and contact center offerings:
- Acquisition of LumenVox, a San Diego-based speech and voice technology provider
- Acquisition of CereProc, specializing in scalable synthesized voices
- Acquisition of SmartAction, which provides AI-powered virtual agents for contact centers
- SoundHound's Acquisition of SYNQ3 Restaurant Solutions SoundHound acquired SYNQ3, a provider of voice AI and other technologies for restaurants. This acquisition was strategically aimed at strengthening SoundHound's voice ordering solutions for the restaurant industry, showcasing the growing importance of audio AI in specific vertical markets.
- WaveForms AI Funding A former OpenAI researcher launched WaveForms AI, a startup focused on creating emotionally engaging voice interactions using AI, and secured $40 million in funding.
- Salesforce's Acquisition of Tenyx Salesforce acquired Tenyx, an AI voice agent company serving industries like e-commerce and healthcare. This acquisition aligns with Salesforce's strategy to enhance its AI capabilities in voice recognition and interaction, indicating the growing importance of audio AI in customer relationship management and service industries.
- In June 2024, Amazon's Deal with Adept: Amazon reached a deal with AI startup Adept, which included hiring key executives and licensing its technology. While not exclusively focused on audio AI, this move aims to bolster Amazon's capabilities in artificial general intelligence, which has significant implications for advancements in audio AI recognition and natural language processing.
- In April 2024, Microsoft's Acquisition of Inflection AI Microsoft acquired Inflection AI, securing rights to offer its AI model via Azure Cloud. This acquisition, which included hiring Inflection's co-founders and employees, enhances Microsoft's consumer AI division. While not solely focused on audio AI, this move strengthens Microsoft's overall AI capabilities, which are likely to have positive implications for audio recognition technologies.
- Lenovo's Launch of AI Now Platform Lenovo introduced "Lenovo AI Now," a local AI agent designed to transform traditional PCs into personalized AI devices. This platform leverages a local Large Language Model (LLM) built on Meta's Llama 3, enabling real-time interaction with a user's personal knowledge base.
- Microsoft's Azure AI Speech Service Updates Microsoft announced updates to its Azure AI Speech service, including the availability of video translation and support for OpenAI text-to-speech voices. Additionally, Microsoft released the Azure AI Speech Toolkit extension for Visual Studio Code
- OpenAI's Major Funding Round OpenAI secured a significant funding round of $6.6 billion, one of the largest in 2024. While OpenAI's work spans various AI domains, their advancements in language models have substantial implications for audio and speech recognition technologies. This massive funding injection is likely to accelerate research and development in AI technologies, including those related to audio recognition.
Market Segmentation Overview:
By Type
- Music recognition
- Speech recognition
- Disability assistance
- Surveillance systems
- Natural sounds recognition
By Device
- Smartphones
- Tablets
- Smart Home Devices
- Smart Speakers
- Connected Cars
- Hearables
- Smart Wristbands
- Others
By Deployment
- On Cloud
- On-Premises/Embedded
By Industry
- Automotive
- Enterprise
- Consumer
- Banking, Finance Service & Insurance (BFSI)
- Government
- Retail
- Healthcare
- Military
- Legal
- Education
- Others
By Region
- North America
- The U.S.
- Canada
- Mexico
- Europe
- The UK
- Germany
- France
- Italy
- Spain
- Poland
- Russia
- Asia Pacific
- China
- Taiwan
- India
- Japan
- Australia & New Zealand
- ASEAN
- Rest of Asia Pacific
- Middle East & Africa (MEA)
- UAE
- Saudi Arabia
- South Africa
- Rest of MEA
- South America
- Brazil
- Argentina
- Rest of South America
View Full Infographic
REPORT SCOPE
| Report Attribute | Details |
|---|---|
| Market Size Value in 2024 | US$ 5.23 Billion |
| Expected Revenue in 2033 | US$ 19.63 Billion |
| Historic Data | 2020-2023 |
| Base Year | 2024 |
| Forecast Period | 2025-2033 |
| Unit | Value (USD Bn) |
| CAGR | 15.83% |
| Segments covered | By Type, By Device, By Deployment, By Industry, By Region |
| Key Companies | Amazon.com, Inc., Google, Uniphore, Speechmatics, SoapBox Labs, Otter.ai, Verbit, Mobvoi, Nuance, iFLYTEK, Sensory, Other prominent players |
| Customization Scope | Get your customized report as per your preference. Ask for customization |
LOOKING FOR COMPREHENSIVE MARKET KNOWLEDGE? ENGAGE OUR EXPERT SPECIALISTS.
SPEAK TO AN ANALYST
.svg)


Choose License Type


Features | Type of License | ||||
Data Book | Single User |   Multi User | Corporate | ||
| e-Access | ✓ | ✓ | ✓ | ✓ | |
User Sharing | 1 User Only | 1 User Only | Up to 7 Users | Unlimited User Access | |
⨉ | ⨉ | ⨉ | ✓ | ||
Free Customization | No Free Customization | Up To 30 hrs work | Up To 60 hrs work | Up To 80 hrs work | |
Deliverable |
| ⨉ | ✓ | ✓ | ✓ |
| ✓ | ⨉ | ✓ | ✓ | |
| ⨉ | ⨉ | ⨉ | ✓ | |
Analyst Support | 2-Months Analyst Support | 4-Months Analyst Support | 7-Months Analyst Support | One Year Analyst Support | |
Free Report update in next update cycle | ⨉ | ⨉ | ⨉ | ✓ | |
Free Industry Update (Within 180 days) | ⨉ | ⨉ | ⨉ | ✓ | |
Benefit | Up to 10% off on Post Purchase | Up to 20% off on Post Purchase | Up to 30% off on Post Purchase | Up to 40% off on Post Purchase | |

